June 16, 2019
Desacoplando la entrega de software de los sistemas de control de versiones
Como una extensión más de la
ley de Conway, es muy habitual
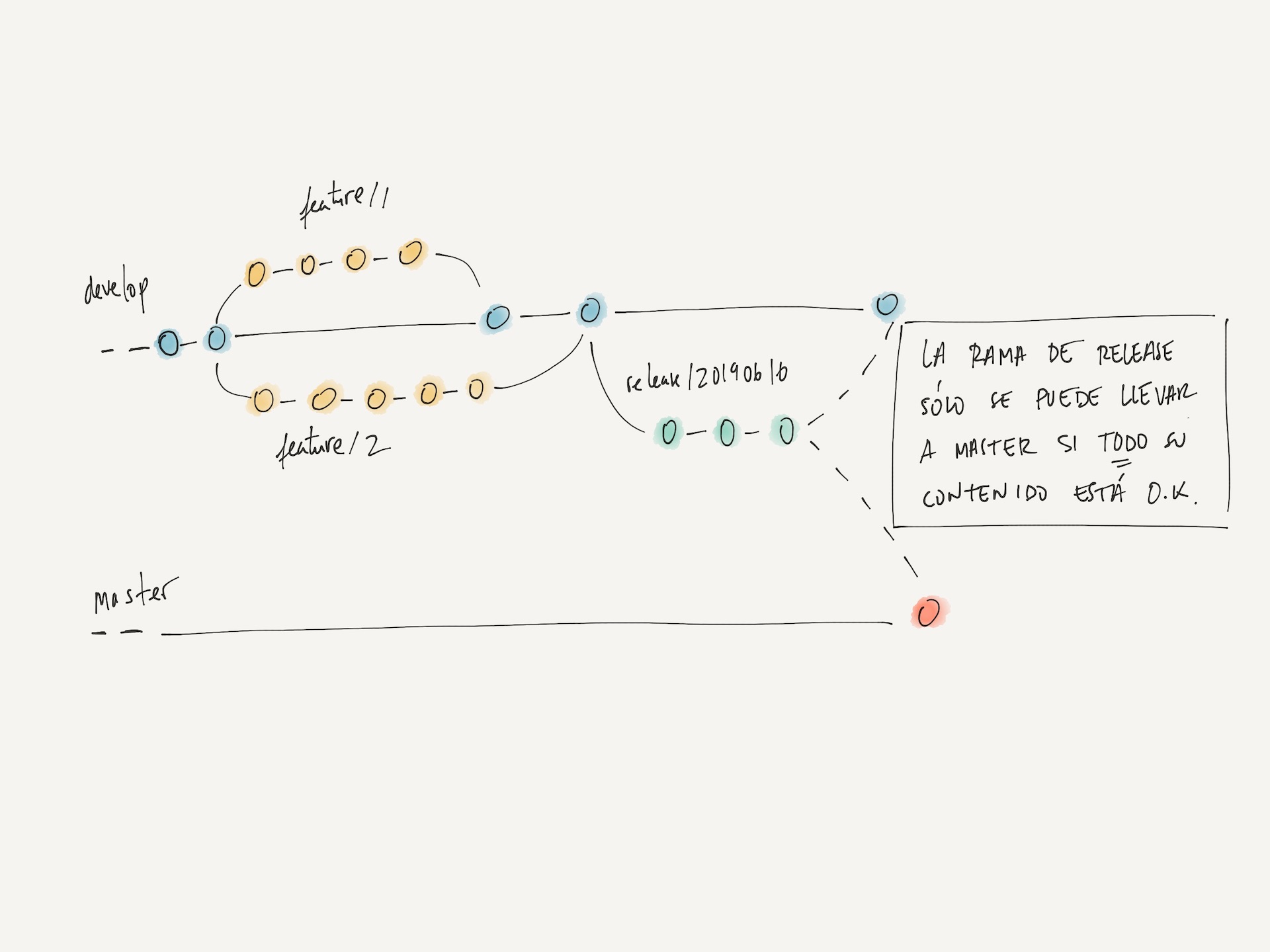
encontrarse con proyectos donde la estrategia de branching del sistema de
control de versiones está fuertemente relacionada con la estrategia de entrega
de software. Esta relación entre ambos mundos puede parecer conveniente (por
ejemplo: utilizar una rama para representar el código vivo en producción o
staging, congelar los cambios que van a desplegarse en una rama release/*,
etc.) pero, con el paso del tiempo, puede traer consigo efectos
contraproducentes:
- Viola el principio de responsabilidad única. Si algo nos queda claro sobre el Single Reponsability Principle es que cada abstracción sólo debe tener una única razón para cambiar (en palabras de Robert C. Martin). Si cambios en los procesos de entrega de software (flujos de resolución de hotfixes, nuevos entornos) implican cambios en la estructura de nuestro repositorio (o cambios en la manera de interactuar con él), los límites entre ambos contextos no están bien establecidos.
- Todo se vuelve innecesariamente complejo. Aún con flujos muy populares
como
git-flow(y herramientas muy sofisticadas a su alrededor, construidas como una capa de abstracción sobregit), se hackea el sistema de control de versiones para dejar de ser una herramienta de tracking y colaboración por un sistema de despliegue y configuración. - Resta flexibilidad. Si es el sistema de control de versiones el encargado de determinar qué funcionalidades se van a liberar al final de una iteración, se pueden dar situaciones en las que una rama se quede congelada por contener funcionalidad defectuosa que inevitablemente contamina al resto de cambios de esa misma rama, bloqueando la entrega de nueva funcionalidad.
Para aliviar los problemas anteriores, una solución pasa por mover la responsabilidad de decidir qué funcionalidades están disponibles en cada entorno desde el sistema de control de versiones a la propia base de código. Es decir, decidir programáticamente si una funcionalidad está habilitada o no en función de en qué entorno se está ejecutando la aplicación.
Una representación habitual de este principio es a través del uso de Feature Flags, que no dejan de ser, conceptualmente, bloques condicionales que se sitúan en algún punto de nuestra base de código y deciden si un camino de ejecución debe evaluarse o no.
Con esta estrategia, únicamente necesitaríamos una rama master donde fusionar
las feature branches de funcionalidades terminadas y una configuración de
feature flags que defina los entornos en los que estarían disponibles. Por
ejemplo: habilitar la funcionalidad únicamente en entornos de staging para
realizar pruebas de rendimiento, labores de quality assurance, etc. La
resolución de hotfixes, se podría realizar igualmente sobre la rama master,
pues es esta la que siempre se despliega y define qué funcionalidades estarían
disponibles en cada momento y para cada entorno.
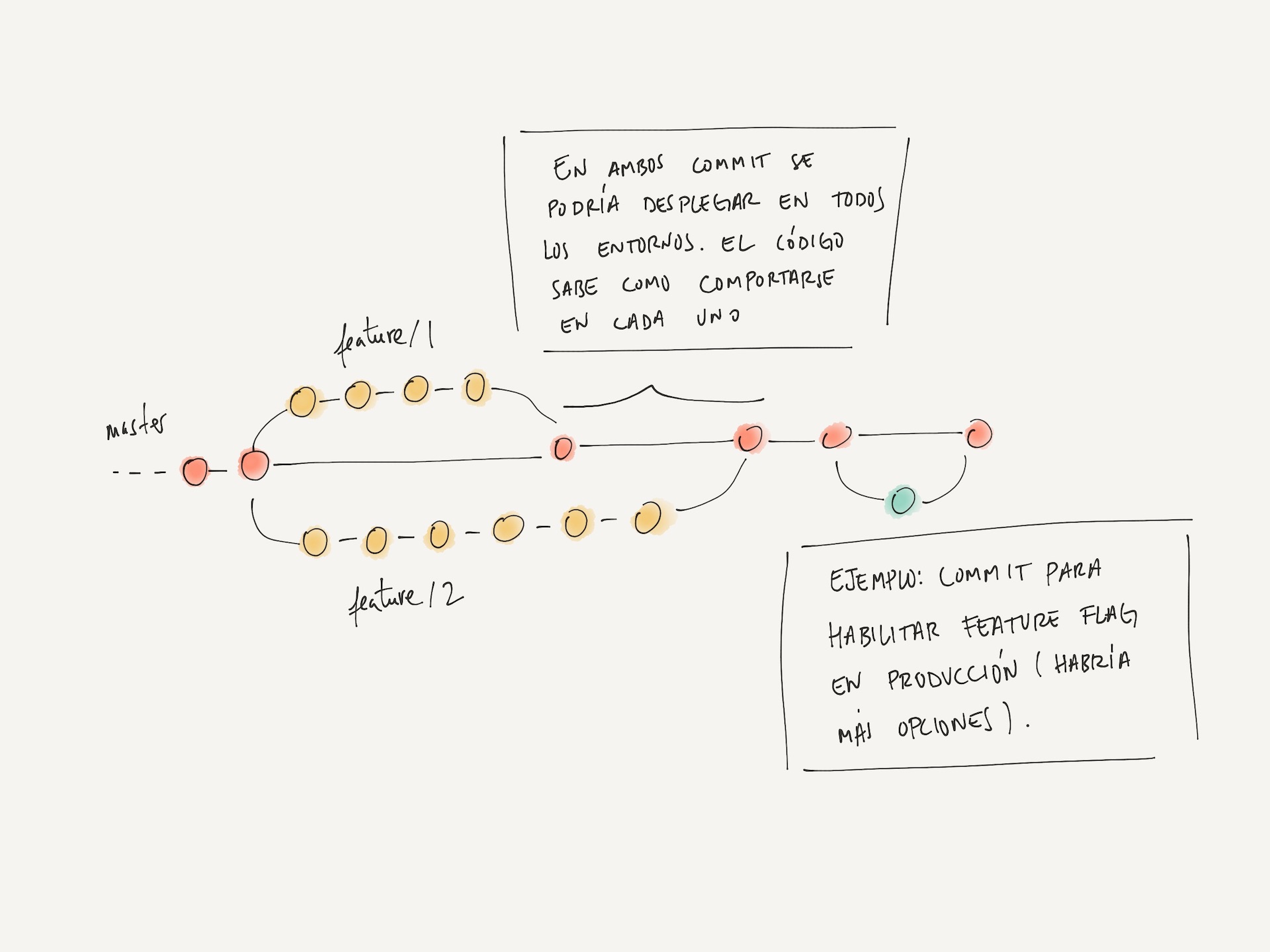
Siguiendo esta dirección, también se obtendrían beneficios adicionales como, por ejemplo, poder realizar merges de manera mucho más recurrente (al estar el entorno de producción siempre protegido a través de feature flags). Esto podría derivar, a su vez, en procesos de code review con un número menor de cambios y ciclos de feedback más cortos, siempre que lo combinemos con técnicas como continuous integration y continuous delivery.